

{kind=link}
はじめに[]
{kind=link}
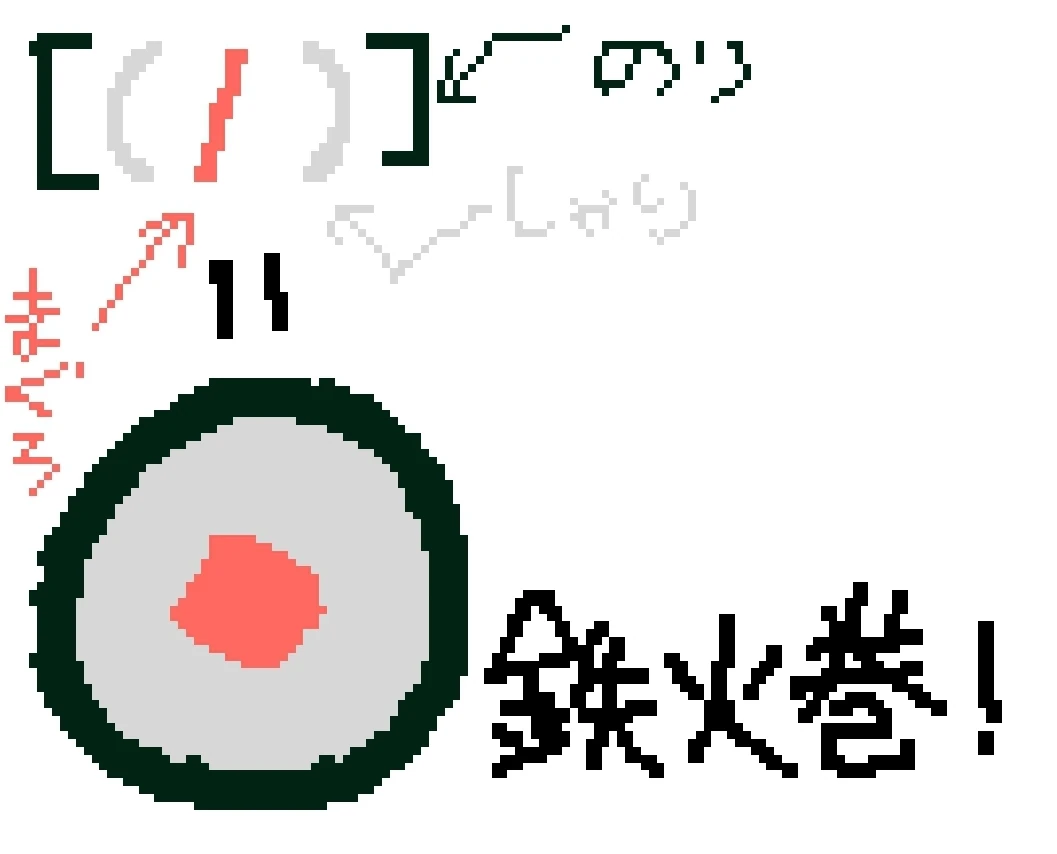
鉄火巻き(TEKKAMAKI)のイメージ。海苔(NORI)の中にシャリ(SHARI)があってその中にマグロ(TUNA)がある事が分かる。
{kind=link}
TRTRITEKAMAKION(トルトライテカマキオン)を鉄火巻きで表したもの。とってもキモくなっている。
ブログ記事のユーザーブログ:Merliborn/ヴェブレンのφ記法とヴェブレン階層 を見てウェブレン関数の理解が進んだ。そこで、その記事の中の「 \(\varphi(x_{0})=\omega^{x_{0}}\) を基にした表記」の基本列をもとにして巨大数を作ってみた。2020年2月20日にスプレッドシートで定義を公開し[1] 、(2020/02/25追記:2020/02/24にOkkuuさんがコメント欄にて解析を行ってくださいました。ブログ本文中に記載した解析結果はそのコメントの内容を参考にしたものとなっています。)
特徴[]
この表記は超限変数ウェブレン関数の基本列をカッコの文字列に翻訳し、その文字列にハイパー二項演算子に近い役割を持たせたものである。これにより極限が急増加関数、Weiermannの\(\vartheta\)で \(f_{\vartheta(\Omega^\Omega)}(n)\) 相当になる表記となった。この表記はHarvey FriedmanのTREE数列において、 \(TREE(n)\) の増大度の下限にあたる関数より強い。そして、Chris BirdのH関数における \(H(n)\) より弱い。文字列操作と計算操作が完全に分離しているため、文字列とその操作の部分を使って順序数を添え字に持つような関数にそのまま適用し、巨大関数にすることができる。そこで、文字列を急増加関数、ハーディ階層、緩増加関数にそれぞれ適用させ作った関数を参考の欄に記した。
文字列の定義[]
文字列 \( \alpha \) が空列であることを \( \alpha = \varnothing \) と書く
文字列 \( \alpha \) が集合 \(T\) に含まれることを \(α \in T \) と書く
\( (,/,),[,] \) でできた文字列の集合 \(T\) を、以下に再帰的に定義する
- \(\alpha = \varnothing\) なら \(α \in T \)
- \(\alpha \in T\) なら \([( \alpha /)] \in T \)
- \(\alpha ,\beta \in T \) なら \( \alpha \beta \in T \)
- \([(\alpha_{1}/\beta_{1})\cdots(\alpha_{n}/\beta_{n})(\gamma/)] \in T \)
- ただし \(\small \alpha_{1},\cdots,\alpha_{n},\beta_{1},\cdots,\beta_{n},\gamma \in T \)、\(\small \alpha_{1},\cdots,\alpha_{n},\beta_{1},\cdots,\beta_{n} \neq \varnothing \) 、 \(\small \beta_{1},\cdots,\beta_{n} \)は互いに異なる。
文字列変換関数 \(\{m,X\}\) の定義[]
\(\alpha,\beta,\gamma,\rho,a,b,c \in T\) 、 \(D,d\) は任意文字列とする。互いに異なる文字列\(x,X \in T \) 、 \(0\) 以上の整数 \(m\) に対し \(\{m,X\}=x\) とする。\(X\) についてもっとも右にある部分文字列 \(/)\) を \(S\) とする。このとき、 \(\delta_{1} \in T\) 、 \(\delta_{2}\) を任意文字列として、\(X=\delta_{1}[\delta_{2}(\gamma S]\)が成り立つ。また、 \[\rho= \begin{cases} \varnothing & ( \gamma=\varnothing ) \\ [\delta_{2}(c/)] & ( \gamma=c[(/)] ) \end{cases} \] とする。 以下の操作で生成された文字列\(D\) の部分文字列 \(/)(/)\) を \(/)\) に置換し、 \((/)]\) となる\((/)\) 以外の \((/\beta)\) を削除した文字列を \(x\) とする。
- 1. \(\gamma \neq \varnothing\) かつ \(\gamma \neq c[(/)]\) のとき、\(D=\delta_{1}[\delta_{2}(\{m,\gamma\}/)]\).
- 2. \(\gamma\) がそれ以外のとき
- 1. \(\delta_{2}=d(\alpha/\beta)\) のとき、
\( \hspace{40pt} D= \begin{cases} \delta_{1}\underbrace{[d(a/\beta)([\cdots[d(a/\beta)(}_{m個の[d(a/\beta)(}\,\rho[(/)]\,\underbrace{/b)(/)]\cdots]/b)(/)]}_{m個の/b)(/)]} & ( \alpha=a[(/)] \ かつ \ \beta=b[(/)] ) \\ \delta_{1}[d(a/\beta)([(/)]/\{m,\beta\})(\rho[(/)]/)] & ( \alpha=a[(/)] \ かつ \ \beta \neq b[(/)] ) \\ \delta_{1}[d(\{m,\alpha\}/\beta)(\rho[(/)]/)] & (\alpha \neq a[(/)]) \end{cases} \)
- 2. \(\delta_{2}=\varnothing\)のとき、
\( \hspace{40pt} D= \begin{cases} \delta_{1}\underbrace{\rho \cdots \rho}_{m}[(/)] & ( \gamma=c[(/)] ) \\ \delta_{1} & (\gamma=\varnothing) \end{cases} \)
巨大表記「TEKKAMAKI notation」の定義[]
\(m_{1},m_{2}\) を \(0\) 以上の整数、 \(X \in T\)かつ\(X\neq\varnothing\)としたとき、表記「TEKKAMAKI notation」を以下に再帰的に定める
- \(m_{1}Xm_{2}\) はTEKKAMAKI notationである
- \(y,z\) がTEKKAMAKI notationであるとき、\(yXz\)はTEKKAMAKI notationである
ここで\(yXz\) について、Xを鉄火巻(TEKKAMAKI)と呼ぶ。この時任意文字列 \(a,b,c,d\) について、
\(X=a[b]c\) の \([\,]\) は海苔(NORI)、 \(X=a(b/c)d\) の \(()\) はシャリ(SHARI)、 \(/\) はマグロ(TUNA)と呼ぶ。
計算[]
TEKKAMAKI notation は右から計算する。\(m_{1},m_{2}\) を \(0\) 以上の整数、 \(X,Y \in T\)かつ\(X,Y\neq\varnothing\)とする。与えられたTEKKAMAKI notation について、一番右の \(m_{1}Xm_{2}\) を見つけ、それ以外の部分を \(\&\) として場合分けする。 \(m_{1}\) に後者関数を \(m_{2}\) 回適用した結果得られる数を \(m_{1}+m_{2}\) とする。
\( \hspace{25pt} \&m_{1}Xm_{2}= \begin{cases} \&m_{1}+m_{2} & (X=[(/)] または m_{2}=0) \\ \&\underbrace{m_{1}Ym_{1}Y \cdots m_{1}Ym_{1}}_{m_{2}個のm_{1}} & (X=Y[(/)]) \\ \&m_{1}\{m_{2},X\}m_{2} & (otherwise) \end{cases} \)
極限[]
\[ n\underbrace{[([(/)]/[([(/)]/\cdots[([(/)]/[([(/)]/}_{n個の[([(/)]/}\cdots\underbrace{)(/)])(/)]\cdots)(/)])(/)]}_{n個の)(/)]}n \]
の強さはWeiermannの\(\vartheta\)において、\(f_{\vartheta(\Omega^\Omega)}(n)\)となる。ここで、超限変数ウェブレン関数により、 \begin{align} \vartheta(\Omega^\Omega) &=\scriptsize \begin{pmatrix}1\\ \begin{pmatrix}1\\ \begin{pmatrix}1\\ \begin{pmatrix}1\\ \cdots \end{pmatrix} \end{pmatrix} \end{pmatrix} \end{pmatrix} \\ &=\textrm{LVO}(大ウェブレン順序数) \end{align} となる。
計算の例[]
こんな感じで計算するよ \begin{align} 3[([(/)]/[(/)])(/)]3 &= 3[([([([(/)]/)]/)]/)]3 \\ &=3[([([(/)][(/)][(/)][(/)]/)]/)]3 \\ &=\cdots \end{align}
解析[]
小さい巨大数の解析
| 表記 | 解析 | 急増加関数 | ハーディ階層 |
|---|---|---|---|
| \(3[(/)]3\) | \(=6 \ (=3+3)\) | \(f_{0}(3)=4\)*1 | \(H_{0}(3)=3\) |
| \(3[(/)][(/)]3\) | \(=9 \ (=3 \times 3)\) | \(f_{1}(3)=6\) | \(H_{1}(3)=4\) |
| \(3[(/)][(/)][(/)]3\)*2 | \(=27 \ (=3 \uparrow 3)\) | \(f_{2}(3)=24\) | \(H_{2}(3)=5\) |
| \(3[(/)][(/)][(/)][(/)]3\)*3 | \(=7625597484987 \ (=3 \uparrow\uparrow 3 \ =3 \uparrow 3 \uparrow 3)\) | \(f_{3}(3)\lesssim 9\uparrow\uparrow 3\) | \(H_{3}(3)=6\) |
| \(3[([(/)]/)]3\) | \(=7625597484987\) | \(f_{\omega}(3)\lesssim 9\uparrow\uparrow 3\) | \(H_{\omega}(3)=6\) |
| \(3[([(/)]/)][(/)]3\) | \(=3 \underbrace{\uparrow\cdots\uparrow}_{3 \uparrow\uparrow 3} 3\) | \(f_{\omega+1}(3)\lt \{3,4,1,2\} = 3\underbrace{\uparrow\cdots\uparrow}_{3\underbrace{\uparrow\cdots\uparrow}_{3\underbrace{\uparrow\cdots\uparrow}_{3\uparrow\uparrow\uparrow 3} 3} 3} 3\) | \(H_{\omega+1}(3)=8\) |
*1なんで0から始まっているのかというと、TEKKAMAKI notationで \(\omega\) にあたる文字列\([([(/)]/)]\) (ここではこれも単に \(\omega\) と呼ぶ)の文字列変換関数について \(\{0,\omega\}=[(/)]\) が成り立つから。
*2: \(3[(/)][(/)][(/)]3\) の計算
\begin{align} 3[(/)][(/)][(/)]3 &=3[(/)][(/)]3[(/)][(/)]3\\ &=3[(/)][(/)]3[(/)]3[(/)]3\\ &=3[(/)][(/)]9\\ &=3[(/)]3[(/)]3[(/)]3[(/)]3[(/)]3[(/)]3[(/)]3[(/)]3=27\\ \end{align}
*3: \(3[(/)][(/)][(/)][(/)]3\) の計算
\begin{align} 3[(/)][(/)][(/)][(/)]3 &=3[(/)][(/)][(/)]3[(/)][(/)][(/)]3\\ &=3[(/)][(/)][(/)]3[(/)][(/)]3[(/)][(/)]3\\ &=3[(/)][(/)][(/)]3[(/)][(/)]9\\ &=3[(/)][(/)][(/)]27=3^{27}=3^{3^{3}}\\ &=7625597484987 \end{align}
巨大数の命名[]
命名した巨大数とその解析
| 命名 | 対応する表記 | 解析 |
|---|---|---|
| TRION(トライオン) | \(3[(/)][(/)][(/)]3\) | \(=27\) |
| TRTRION(トルトライオン) | \(3[([([(/)]/)]/)]3\) | 下限 \(f^2_{\omega^33}(3)\) 上限 \(f^2_{\omega^33}(4)\) |
| MAKION(マキオン) | \(3[([(/)]/[(/)])(/)]3\) | 下限 \(f^2_{\omega^{\omega^33}3}(3)\) 上限 \(f^2_{\omega^{\omega^33}3}(4)\) |
| TRIMAKION(トライマキオン) | \(3[([(/)]/[(/)])([(/)][(/)][(/)]/)]3\) | \(\fallingdotseq f_{\varepsilon_2^{\varepsilon_2^2}}(3)\) |
| TRTRIMAKION(トルトライマキオン) | \(3[([(/)]/[(/)])([([([(/)]/)]/)]/)]3\) | \(\fallingdotseq f_{\varepsilon_{\omega^33+1}}(3)\) |
| MAKIMAKION(マキマキオン) | \(3[([(/)][(/)]/[(/)])(/)]3\) | \(\fallingdotseq f_{\varepsilon_{\varepsilon_{\varepsilon_1}}}(3)\) |
| TECKION(テッキオン) | \(3[([(/)][(/)][(/)]/[(/)])(/)]3\) | \(\fallingdotseq f_{\zeta_{\zeta_{\zeta_1}}}(3)\) |
| TRTECKION(トルテッキオン) | \(3[([([([(/)]/[(/)])(/)]/[(/)])(/)]/[(/)])(/)]3\) | \(\fallingdotseq f_{\varphi(\varphi(\varepsilon_0,0),0)}(3) \ (\fallingdotseq f_{\vartheta(\Omega\vartheta(\Omega\vartheta(0)))}(3))\) |
| TRTRITECKION(トルトライテッキオン) | \(3[([(/)]/[(/)][(/)])(/)]3\) | \(\fallingdotseq f_{\varphi(\varphi(\varepsilon_0,0),0)}(3)\)*1 |
| TECKAMAKION(テッカマキオン) | \(3[([(/)]/[(/)][(/)][(/)])(/)]3\) | \(\fallingdotseq f_{\varphi(\varphi(\Gamma_0,0,0),0,0)}(3) \ (\fallingdotseq f_{\vartheta(\Omega^{2}\vartheta(\Omega^{2}\vartheta(\Omega^{2})))}(3))\) |
| TRTECKAMAKION(トルテッカマキオン) | \(3[([(/)]/[([(/)]/)])(/)]3\) | \(\fallingdotseq f_{\varphi(1,0,0,0,1)}(3) \ (\fallingdotseq f_{\vartheta(\Omega^{\omega}\vartheta(\Omega^{\omega}\vartheta(\Omega^{\omega})))}(3))\) |
| TRTRITEKAMAKION(トルトライテカマキオン) | \(3[([(/)]/[([(/)]/[([(/)]/[(/)])(/)])(/)])(/)]3\) | \(\fallingdotseq f_{\vartheta(\Omega^{\vartheta(\Omega^{\varepsilon_0})})}(3)\)*2 |
*1:TRTECKIONとTRTRITECKIONの大きさは厳密に一致する。
*2:
\(\vartheta(\Omega^{\vartheta(\Omega^{\varepsilon_0})})=\begin{pmatrix}1\\\begin{pmatrix}1\\\varepsilon_0\end{pmatrix}\end{pmatrix}\)
参考:さまざまな関数の定義に沿わせた巨大関数[]
同じように\(X \in T\) と \(\{n,X\}\)を使う巨大関数でも、それらをどんな出力に適用させるのかによって大きさは大きく異なってしまう。
- 1. 急増加関数(実際の定義は急増加関数)
- \(0\)以上の整数\(n\)、文字列\(X,Y \in T\)に対して自然数から自然数への関数\(TF_{X}(n)\)を定める。
- \(0\)以上の整数\(n\)、文字列\(X,Y \in T\)に対して自然数から自然数への関数\(TF_{X}(n)\)を定める。
\( \hspace{40pt} TF_{X}(n)= \begin{cases} n+1 & (X=\varnothing) \\ TF_{Y}^{n}(n)=\underbrace{TF_{Y}(TF_{Y}( \cdots TF_{Y}(}_{n}n\underbrace{) \cdots ))}_{n} & (X=Y[(/)]) \\ TF_{\{n,X\}}(n) & (otherwise) \end{cases} \)
- 2. ハーディ階層(実際の定義はハーディ階層)
- \(0\)以上の整数\(n\)、文字列\(X,Y \in T\)に対して自然数から自然数への関数\(TH_{X}(n)\)を定める。
- \(0\)以上の整数\(n\)、文字列\(X,Y \in T\)に対して自然数から自然数への関数\(TH_{X}(n)\)を定める。
\( \hspace{40pt} TH_{X}(n)= \begin{cases} n & (X=\varnothing) \\ TH_{Y}(n+1) & (X=Y[(/)]) \\ TH_{\{n,X\}}(n) & (otherwise) \end{cases} \)
- 3. 緩増加関数(実際の定義は緩増加関数)
- \(0\)以上の整数\(n\)、文字列\(X,Y \in T\)に対して自然数から自然数への関数\(TG_{X}(n)\)を定める。
- \(0\)以上の整数\(n\)、文字列\(X,Y \in T\)に対して自然数から自然数への関数\(TG_{X}(n)\)を定める。
\( \hspace{40pt} TG_{X}(n)= \begin{cases} 0 & (X=\varnothing) \\ TG_{Y}(n)+1 & (X=Y[(/)]) \\ TG_{\{n,X\}}(n) & (otherwise) \end{cases} \)
- 4. 緩々々々増加関数(実際の定義は緩々々々増加関数)
- \(0\)以上の整数\(n\)、文字列\(X,Y \in T\)に対して自然数から自然数への関数\(TS_{X}(n)\)を定める。
- \(0\)以上の整数\(n\)、文字列\(X,Y \in T\)に対して自然数から自然数への関数\(TS_{X}(n)\)を定める。
\( \hspace{40pt} TS_{X}(n)= \begin{cases} 1 & (X=\varnothing) \\ TS_{Y}(n+1) & (X=Y[(/)]) \\ TS_{\{1,X\}}(TS_{\{1,X\}}(0))+1 & (X=otherwise かつ n=0) \\ TS_{\{n,X\}}(n) & (X=otherwise かつ n\neq0) \end{cases} \)
基本列の取り方にもよるがふつうに使われる基本列を採用すれば[2]、以下のことが成り立つといわれている。
- 「十分に大きなnについて」ハーディ階層 \(H_{\varepsilon_{0}}(n)\) は急増加関数 \(f_{\varepsilon_{0}}(n)\) と同じぐらいの強さになる。
- 「十分に大きなnについて」ブーフホルツの\(\psi\)を使って緩増加関数 \(g_{\psi_0(\Omega_\omega)}(n)\) は急増加関数 \(f_{\psi_0(\Omega_\omega)}(n)\) と同じぐらいの強さになる。
- 順序数 \(\alpha\) 、について、\(g_{\alpha}(n) \leqq H_{\alpha}(n) \leqq f_{\alpha}(n)\)が成り立つ。
「十分に大きなnについて」の「十分な」がどれくらいなのかは分からない。えのきさんのツイート[3]によると、ワイナー階層で定義された基本列を採用すると、 \(H_{\varepsilon_{0}}(100)=f_{\varepsilon_{0}}(99) \lt f_{\varepsilon_{0}}(100) \) となる。また、どんな基本列を採用したのかは不明だが、大ウェブレン順序数については\(g_{\vartheta(\Omega^\Omega)}(n)\fallingdotseq f_{\omega^{\omega}+1}(n)\) という関係がある。TEKKAMAKI notation の計算について、 \(nXm\) を \(TN_{X}(n,m)\) とおくと以下のように書き直すことができる。
\( \hspace{25pt} TN_{X}(n,m)= \begin{cases} n+m & (X=[(/)] または m=0) \\ \underbrace{TN_{Y}(n,TN_{Y}(n, \cdots TN_{Y}(n,}_{m-1}n\underbrace{) \cdots ))}_{m-1} & (X\neq[(/)] かつ X=Y[(/)]) \\ TN_{\{n,X\}}(n,m) & (otherwise) \end{cases} \)
これをみるとXが後続順序数に当たる構造の時に反復合成を課しているため、急増加関数っぽい挙動を持っていることが分かる。\(m=n\)の場合、解析の結果から、急増加関数より増加速度が遅く、ハーディ階層より早く増大する(かもしれない)[4]。
脚注[]
- ↑ 公開したスプレッドシートへのリンク→[1]。定義が微妙に異なっているが、やっていることは同じ。
- ↑ 普通じゃないやつを採用すると、関数が壊れる(順序数の順序が大きくなっても関数が強化されない)ことがある。普通じゃないやつというのは、例えば基本列がめちゃくちゃ弱かったり(例えばほとんど値が変わらなかったり)、ある所だけ0になるように仕組まれた基本列だったりするやつのこと。またこれとは別に関数の階層そのものの「後続順序数に対して行う操作の強さ」に起因して壊れることがある。関数の階層は添え字の順序数の基本列に依存して出力が決まる。この依存度合いが高いと、基本列を少し弱くしただけで関数の強化のかかり方が大きく弱まってしまい、場合によっては関数が壊れてしまう(このことを「基本列に敏感」という)。後続順序数に対して行う操作が弱いほど基本列への依存度合いが高くなるため、後続順序数に対して行う操作の強さがハーディ階層や急増加関数より弱く「基本列に敏感」な緩増加階層は、その2つより壊れやすいと言える。ここら辺の議論についての詳しいことはここのツリーまたはここを見てね。
- ↑ https://twitter.com/enoki_fugue/status/1233207331720171520
- ↑ \(X\)を要素として持っている集合\(T\)には順序が定義されておらず、標準形も定義されていない。文字列変形関数\(\{n,X\}\)はあくまで出力される形が実際の基本列と同じ形になるように調整されているだけで、n番目の基本列を出力しているわけではない。